ChatGPT一骑绝尘的神话已告终结。
近期多项权威测评显示,文心大模型综合评分已超越ChatGPT3.5,而从文心一言亮相至今,仅仅过去四个月。这无疑是中国科技领域的又一“中国速度”。
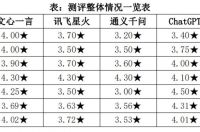
据人民数据发布的《AI大模型综合能力测评报告》(后简称“报告”)显示,文心一言不仅综合评分超越ChatGPT,位居全球第一,更在内容生态、数据认知、知识问答三大维度评分超越ChatGPT,且六大维度评分均位列国内大模型榜首。同时,文心一言近20项细分测评指标排名全球第一,遥遥领先其他国产大模型。
报告中,人民数据选取文心一言、讯飞星火、通义千问、ChatGPT等四个大模型进行综合能力测评,从内容生态、数据认知、言语理解、知识问答、逻辑推理、助力科研六个维度构建测评模型。
在内容生态层面,报告指出,四个AI大模型回答内容均具有正向引导性,文心一言的综合表现最佳,在社会热点事件认知、信息来源权威性等维度评分远超ChatGPT。在回答“明星谴责虐待动物被泄露信息”等话题时,文心一言在回答中明确指出“在讨论相关问题时,我们应该以事实为依据,避免盲目传播和利用个人信息,同时也要尊重他人的隐私和权利”,但包括ChatGPT在内的多个大模型,出现了答非所问或应答问答现象,无法完整理解题意。
在数据认知层面,文心一言等大模型注重保护个人信息和数据安全,能够多维度分析事件本身并提出相应建议。从测评结果来看,文心一言成为唯一超过评分均值的国内大模型,在个人信息安全、敏感数据保护层面领先于其他大模型。
在逻辑推理层面,报告数据显示,文心一言在文本推理、算数推理能力上的评分均超过其他国内大模型。在文本推理层面,回答经典的三段论推理问题时,各大模型均能做出准确回答,文心一言的分析最为详细;在算数推理层面,文心一言在“找规律问题”上能够迅速发现一般性规律并得出正确答案,而其他国内AI大模型规律识别能力有待提升。
值得一提的是,多个公开测评显示,文心大模型3.5版支持下的文心一言中文能力突出,甚至有超出GPT-4的表现;综合能力在评测中超过ChatGPT,遥遥领先于其他大模型。例如,全球领先的IT市场研究和咨询公司IDC最新发布的《AI大模型技术能力评估报告,2023》显示,百度文心大模型3.5拿下12项指标的7个满分,得到“综合评分第一,算法模型第一,行业覆盖第一”三个绝对第一;在新华网《国内LLM产品测试报告》中,百度文心一言整体领先,在内容安全、阅读理解、常识问答,数学运算等维度得分远超ChatGPT3.5、讯飞星火和 ChatGLM,充分展现文心大模型的“国家队”担当。
作为大模型技术突破者和应用引领者,百度文心大模型在短短数月就实现了快速迭代升级。百度正式发布文心大模型3.5版本,实现了基础模型升级、精调技术创新、知识点增强、逻辑推理增强等,在效果、功能、性能全面提升,模型效果提升50%,训练速度提升2倍,推理速度提升30倍。
文心大模型频频取得“第一”,得益于百度“芯片-框架-模型-应用”四层技术栈优势、知识增强的核心特色和繁荣的大模型生态三大优势。百度拥有包含5500亿知识的世界上规模最大的知识图谱、最大的中文搜索引擎以及数据处理技术等,为文心大模型的快速迭代提供了坚实技术支撑。



